Running AI Locally: A Balancer for On-Premise LLM Infrastructure
An LLM-specific load balancer to solve the infrastructure challenge when scaling local AI-agents.
Why Local AI Matters
Running AI locally is important to us, especially when we are dealing with sensitive data of our own and our customers. There are different levels of security or safety, which we can categorize into three main approaches:
- On-Premise: AI models run entirely within our physical infrastructure, with complete control over data and access
- Hosted in the EU: Models run on servers located within the European Union, subject to GDPR and regional compliance
- Any Cloud Anywhere: Models run on public cloud infrastructure that may store and process data across multiple jurisdictions
Each category has its pros and cons. Cloud solutions offer scalability and convenience, while on-premise deployments provide maximum security and control. The hosted EU option sits somewhere in between, offering regional compliance without full infrastructure ownership.
This blog post focuses on the first category - on-premise AI - where we deal with sensitive data that should never leave our infrastructure. This becomes especially critical as AI agents emerge and integrate into virtually every aspect of business operations. We need to run the LLMs for our AI agents locally, on-premise, to maintain data sovereignty and protect customer privacy.
The Fixed Endpoint Problem
Even as a single engineer, I may have two backends, each serving an LLM. When using an agentic system that supports sub-agents, we want to utilize all available hardware by parallelizing across all backends. However, most agentic systems only allow us to configure a single fixed endpoint.
We can technically run multiple requests to the same LLM in parallel, but with large contexts and hardware constraints - especially VRAM - this parallelization becomes less feasible. As a result, all of our sub-agents run sequentially on the same backend. This problem becomes even more pronounced when multiple team members are running agentic systems on a fixed set of backends. Different models hosted on different backends create a configuration mess on the client side, and hardware utilization suffers as some backends sit idle while others get overloaded.
What is needed is a layer that can intelligently distribute work across all available backends.
The LLM Balancer
The solution we built acts as an intelligent load balancer for LLM servers with health checking and automatic failover. It sits as an LLM-specific proxy layer between our AI agents and our backend LLM serving infrastructure.
Architecture Overview
At a high level:
Figure: Multiple AI agents route requests through the LLM Balancer, which distributes them across multiple backend servers (Ollama, LM-Studio, vLLM, and other LLM serving solutions)
Instead of each agent being configured to use a single backend, they all point to the balancer. The balancer then intelligently distributes requests among multiple backends based on:
- Health status: Only healthy backends are considered for routing
- Concurrency limiting: Prevents overloading individual servers with configurable max parallel requests
- Prompt cache matching: Prefer backends with matching prompt cache to reuse KV cache and accelerate processing
- Model matching with regex: Flexible model name mapping across backends with different naming conventions
- Priority-based selection: Among candidates, requests are routed to the highest priority backend first
- Multi-API support: Agents can use any compatible API without knowing the backend details
- FIFO request queuing: When backends are at capacity, requests queue and are processed in order
Additional Features
- Real-Time Dashboard: Monitor backend health, utilization, and queue depth through a web interface
- Comprehensive Statistics: Track request counts, token usage, performance metrics, and prompt cache hits
- Model Auto-Discovery: Pre-populates available models from all backends before requests begin
- Multi-API Auto-Detection: Probes each backend to detect OpenAI, Anthropic, Google Gemini, and Ollama APIs
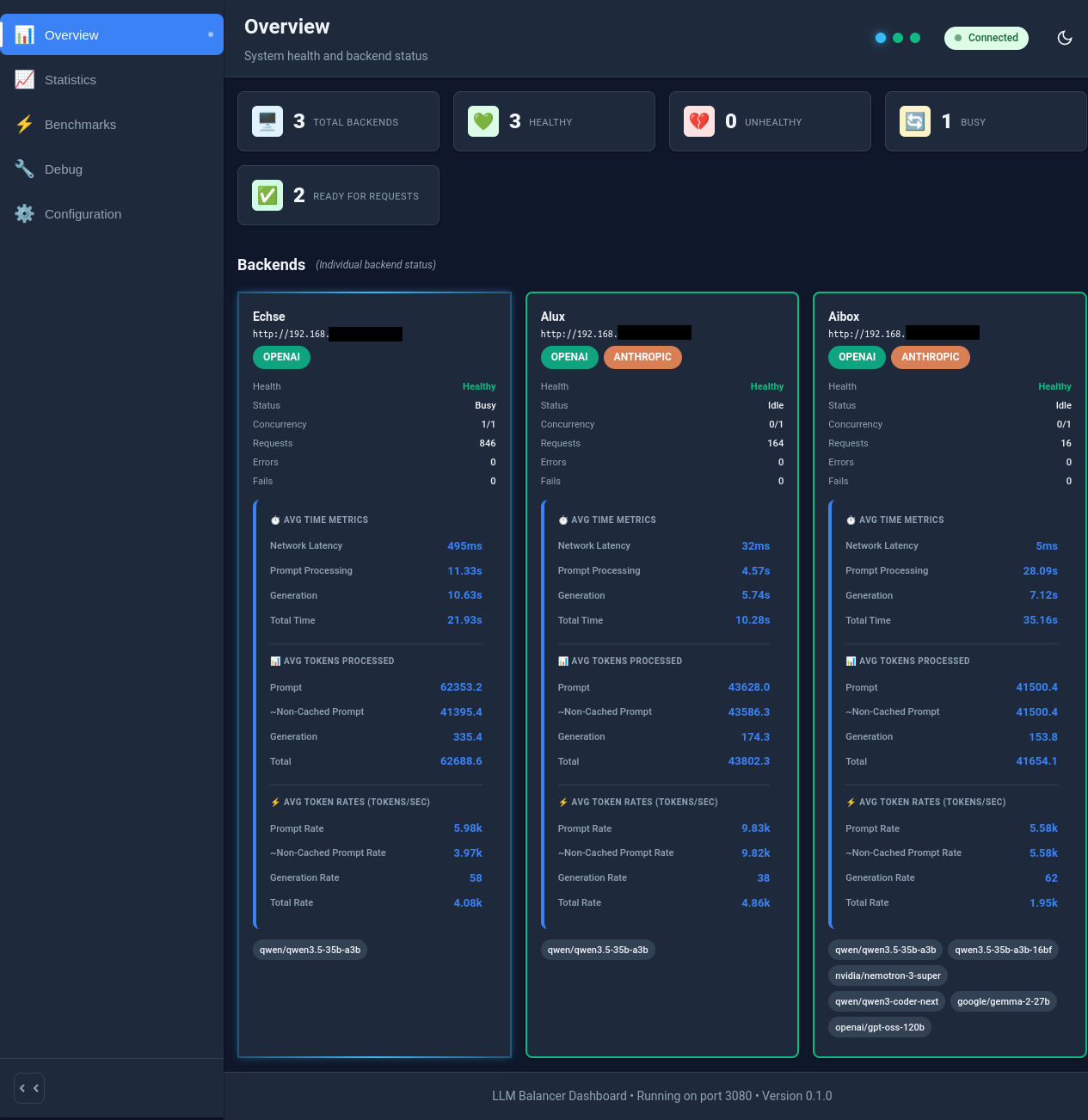
Figure: LLM Balancer Dashboard showing backend health, utilization, and queue depth
Production Experience
We've been using the LLM Balancer in production, and it has been serving its intended purpose really well. Instead of each agentic system being restricted to one fixed LLM endpoint, all of them gain access to the entire backend pool. This has significantly improved our team's throughput and reduced waiting times for LLM responses. Beyond its primary function, the balancer's statistics also enabled us to optimize backend configurations and identify performance bottlenecks.
Detecting Bottlenecks
The balancer's statistics visualization helped us to identify limitations and bottlenecks in our highly diverse backend infrastructure. We were able to compare different LLM-servers, like Ollama, vLLM and LM-Studio on the same hardware. With that, we could identify performance patterns and see which models perform best on which hardware configurations. The throughput measurements were most valuable to configure the backend priorities.
KV Cache Discovery
One of our most important discoveries came from analyzing the balancer's statistics. We found that LM-Studio had a significant problem with mixture-of-experts (MoE) models and KV caches.
- With large contexts, LM-Studio started invalidating KV caches at a certain threshold (e.g. 18k tokens)
- Prompts that were larger than that (e.g. 150k tokens) had to be reprocessed from that threshold.
- Hence, the prompt processing rate degraded significantly after this point with waiting times more than 2 minutes per ping-pong.
Using the balancer's real-time statistics and queue depth visualization, we could easily spot this degradation pattern. The metrics showed a clear degradation of non-cached token rates while the prompt token rate stayed constant, which clearly showed that the prompt was reprocessed entirely from a fixed point. This visibility enabled us to identify the root cause and make informed decisions about which serving solutions to deploy for MoE models.
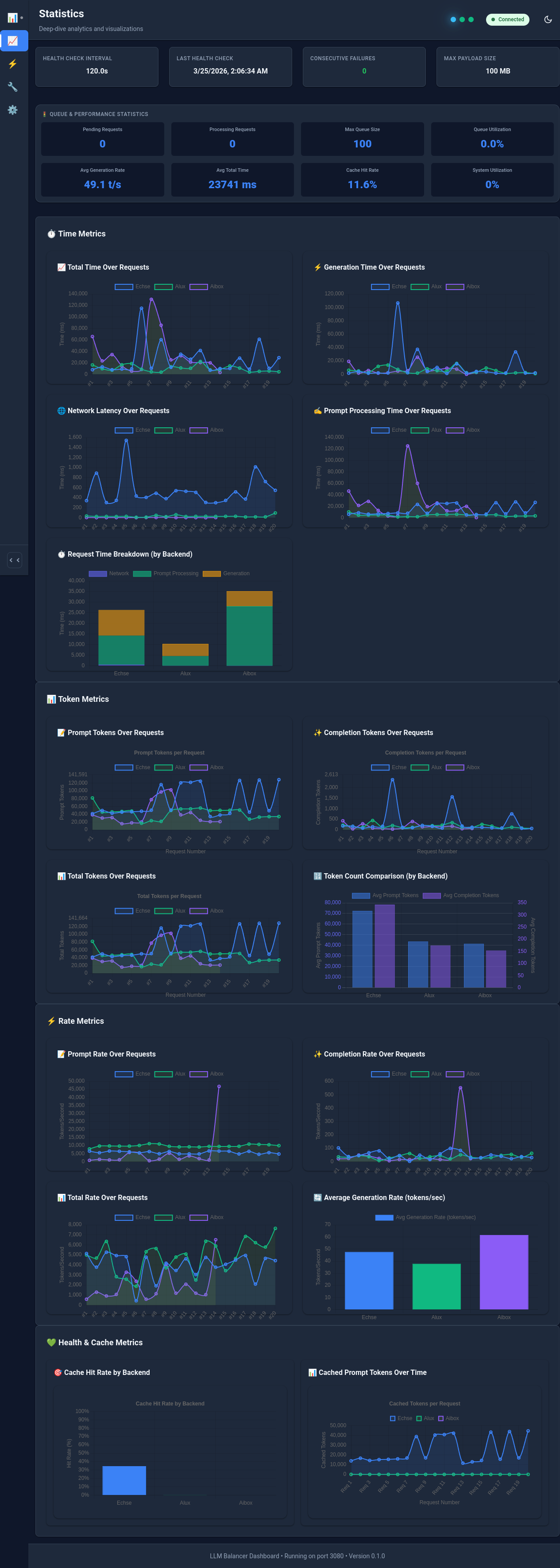
Figure: Balancer statistics showing the degradation pattern in non-cached token rates
This discovery is why we're currently working on a complete restructuring of the statistics component—improving it further to make problem detection even more precise and actionable.
The Future of Local AI
Clearly, agentic systems are becoming increasingly important in nearly every type of work, while humans focus on higher-value activities. We believe the most effective approach for many real-world tasks will be human-agent collaboration, each bringing their strengths to the table. That's why throughput and responsiveness of agentic systems is crucial.
Infrastructure Needs
For this vision to become reality, organizations need reliable infrastructure to utilize available hardware efficiently. As agentic systems become more prevalent, the demand for LLM inference will scale dramatically. Having a balanced, resilient, and observable infrastructure becomes crucial to:
- Maximize hardware utilization across multiple servers
- Ensure consistent availability for agentic workflows
- Scale efficiently as more agents join the system
- Debug and optimize performance bottlenecks
We built this balancer to address these infrastructure needs for our on-premise AI deployments.
Upcoming Features
Beyond our immediate needs, we're continuously improving the balancer. The statistics component is being restructured for more precise problem detection. We're also exploring automated priority setting based on real throughput measurements.
Conclusion
The trend toward local AI is not limited to a few tech-forward companies. As privacy regulations tighten, as data sovereignty becomes more critical, and as organizations seek cost-effective scaling solutions, local AI will become more important for many people and companies.
We're sharing this work as a way to contribute back to the community as we build our own on-premise AI infrastructure.
The full open-source code is now available on GitHub: https://github.com/Schafer-List-Systems/llm_balancer
This blog post documents our experience and insights with building on-premise AI infrastructure for our agentic systems.