KI Lokal Betreiben: Ein Balancer für On-Premise LLM-Infrastruktur
Ein LLM-spezifischer Load Balancer zur Skalierung lokaler KI-Agenten.
Warum Lokale KI Wichtig Ist
KI lokal zu betreiben ist für uns unumgänglich, insbesondere wenn wir mit sensiblen Daten umgehen. Es gibt unterschiedliche Sicherheitsstufen, die wir in drei Hauptansätze kategorisieren:
- On-Premise: KI-Modelle laufen vollständig innerhalb unserer eigenen Infrastruktur, mit vollständiger Kontrolle über Daten und Zugriff
- In der EU gehostet: Modelle laufen auf Servern innerhalb der Europäischen Union, unterliegen der DSGVO und regionaler Compliance
- Any Cloud: Modelle laufen auf Public-Cloud-Infrastruktur, die Daten über mehrere Jurisdiktionen speichern und verarbeiten kann
Jede Kategorie hat ihre Vor- und Nachteile. Cloud-Lösungen bieten Skalierbarkeit und Bequemlichkeit, während On-Premise-Deployments maximale Sicherheit und Kontrolle bieten. Die EU-Hosting-Option liegt dazwischen und bietet regionale Compliance ohne vollständige Infrastruktur-Besitz.
Dieser Blogbeitrag konzentriert sich auf die erste Kategorie - On-Premise-KI - wo wir mit sensiblen Daten umgehen, die unsere Infrastruktur niemals verlassen sollten. Dies wird besonders kritisch, da KI-Agenten zunehmend allgegenwärtig werden. Wir müssen die LLMs für unsere KI-Agenten lokal betreiben, um Datensouveränität zu wahren und Kundendatenschutz zu gewährtleisten.
Das Problem mit Fixed Endpoints
Selbst als einzelner Ingenieur kann ich zwei Backends betreiben, die jeweils ein LLM hosten. Bei der Verwendung eines agentischen Systems, das Sub-Agenten unterstützt, möchten wir alle verfügbare Hardware nutzen, indem wir über alle Backends hinweg parallelisieren. Die meisten agentischen Systeme erlauben uns jedoch nur die Konfiguration eines einzelnen festen Endpoints.
Wir können technisch mehrere Anfragen an dasselbe LLM parallel senden, aber bei großen Kontexten und durch Hardware-Beschränkungen - insbesondere VRAM - wird diese Parallelisierung unmöglich. Infolgedessen laufen alle unsere Sub-Agenten sequentiell auf demselben Backend. Dieses Problem verschärft sich, wenn mehrere Teammitglieder agentische Systeme auf auf mehrere Backends betreiben. Verschiedene Modelle, die auf verschiedenen Backends gehostet werden, verursachen ein Konfigurationschaos auf Client-Seite, und die Hardware-Ausnutzung leidet, da einige Backends untätig bleiben und andere überlastet werden.
Hier bedarf es einer Mittelschicht, welche die LLM Anfragen der agentischen Systeme intelligent über alle verfügbaren Backends verteilt.
Der LLM Balancer
Wir adressieren das oben genannte Problem durch einen intelligenten Load Balancer für LLM-Server mit Health-Checking und automatischem Failover. Er dient als LLM-spezifischer Proxy zwischen unseren KI-Agenten und unserer Backend-LLM-Infrastruktur.
Architektur-Übersicht
Auf hoher Ebene:
Abbildung: Mehrere KI-Agenten routen Anfragen durch den LLM Balancer, der sie auf mehrere Backend-Server verteilt (Ollama, LM-Studio, vLLM und andere LLM-Server-Lösungen)
Agenten werden nun einfach umkonfiguriert, indem sie den Balancer als LLM-Server verwenden, statt eines der Backends direkt. Der Balancer verteilt dann Anfragen intelligent unter mehreren Backends basierend auf:
- Health-Status: Nur healthy Backends werden für das Routing berücksichtigt
- Concurrency-Limiting: Verhindert das Überlasten individueller Server mit konfigurierbaren maximalen parallelen Anfragen
- Prompt-Cache-Matching: Bevorzugt Backends mit übereinstimmendem Prompt-Cache zum Wiederverwenden des KV-Caches und zur Beschleunigung der Verarbeitung
- Modell-Matching mit Regex: Flexible Modellnamenszuordnung über Backends mit unterschiedlichen Namenskonventionen
- Prioritätsbasierte Auswahl: Unter Kandidaten werden Anfragen zuerst an das Backend mit der höchsten Priorität weitergeleitet
- Multi-API-Unterstützung: Agenten können jede kompatible API verwenden, ohne die Backend-Details zu kennen
- FIFO-Anfragenwarteschlange: Wenn Backends am Limit sind, warten Anfragen und werden reihenfolgeweise verarbeitet
Zusätzliche Funktionen
- Echtzeit-Dashboard: Überwachen von z.B. Backend-Gesundheit, Auslastung und Warteschlangenlänge über eine Weboberfläche
- Umfassende Statistiken: Verfolgen von Anfrageanzahlen, Token-Nutzung, Leistungsmetriken und Prompt-Cache-Hits
- Modell-Auto-Discovery: Wird vorab mit verfügbaren Modellen aus allen Backends gefüllt, bevor Anfragen beginnen
- Multi-API-Auto-Erkennung: Sondiert jedes Backend, um OpenAI-, Anthropic-, Google Gemini- und Ollama-APIs zu erkennen
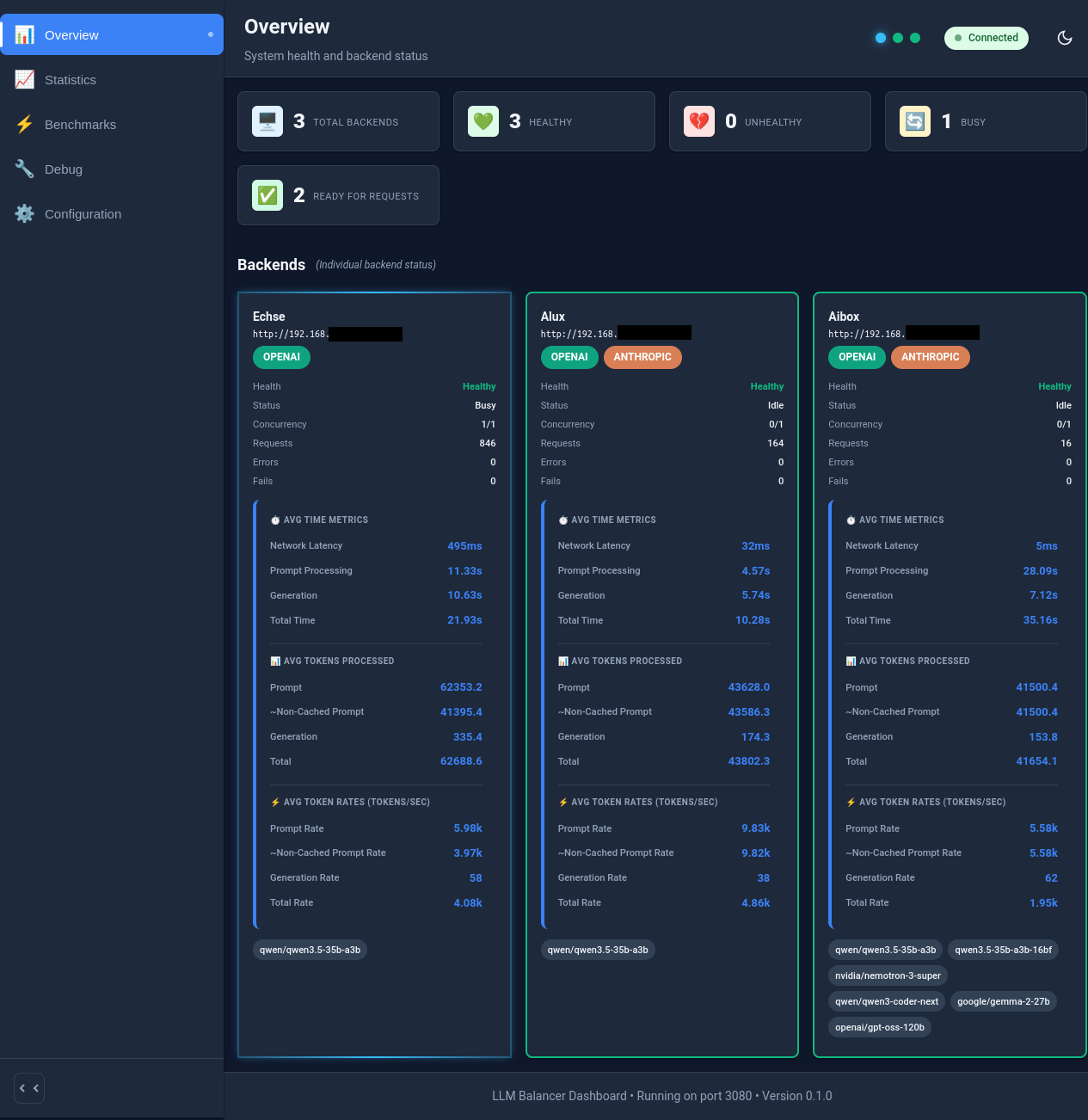
Abbildung: LLM Balancer Dashboard mit Backend-Gesundheit, Auslastung und Warteschlangen-Länge
Einsatz in Produktivem Umfeld
Wir verwenden den LLM Balancer bereits in Produktion, und er erfüllt seinen Zweck hervorragend. Anstatt dass jedes agentische System auf einen festen LLM-Endpoint beschränkt ist, erhalten alle Agenten Zugriff auf den gesamten Backend-Pool. Dies hat den Durchsatz unseres Teams erheblich verbessert und Wartezeiten für LLM-Antworten reduziert. Jenseits seiner Hauptfunktion hat die Statistik des Balancers uns ermöglicht, Backend-Konfigurationen zu optimieren und Leistungsbottlenecks zu identifizieren.
Identifizieren von Bottlenecks
Die Visualisierung der Balancer-Statistiken half uns, Bottlenecks in unserer sehr diversen Backend-Infrastruktur zu identifizieren. Wir haben wertvolle Erkenntnisse über die verschiedenen LLM-Server, wie Ollama, vLLM und LM-Studio, auf derselben Hardware gewonnen. Die sichtbaren Unterschiede zwischen Pipeline-Parallelen und Tensor-Parallen Setups beeinflussen unsere Entscheidung über weitere Anschaffungen maßgeblich. Die Durchsatzmessungen halfen uns, um Backend-Prioritäten zu konfigurieren.
KV Cache und MoE-Modelle
Eine unserer wichtigsten Erkenntnisse kam durch die Analyse der Balancer-Statistiken. Wir stellten fest, dass LM-Studio ein signifikantes Problem mit mixture-of-experts (MoE) Modellen und KV-Caches hat.
- Bei großen Kontexten begann LM-Studio, KV-Caches ab einem bestimmten Schwellwert zu invalidieren (in unserem Beispiel bei 18k Token)
- Größere Prompts (z.B. 150k Token), mussten ab dieser Schwelle erneut verarbeitet werden.
- Folglich nahm die Prompt-Verarbeitungsgeschwindigkeit nach diesem Punkt erheblich ab mit Wartezeiten von mehr als 2 Minuten pro Ping-Pong.
Unter Verwendung der Statistiken im Dashboard des Balancers konnten wir dieses Degradationsmuster leicht erkennen. Die Metriken zeigten einen klaren Abbau der nicht-gecacheten Token-Raten, während die volle Prompt-Token-Rate konstant blieb, was eindeutig zeigte, dass der Prompt von einem festen Punkt aus vollständig erneut verarbeitet wurde. Diese Sichtbarkeit ermöglichte es uns, die Ursache zu identifizieren und fundierte Entscheidungen darüber zu treffen, welche Server-Lösungen für MoE-Modelle eingesetzt werden sollten.
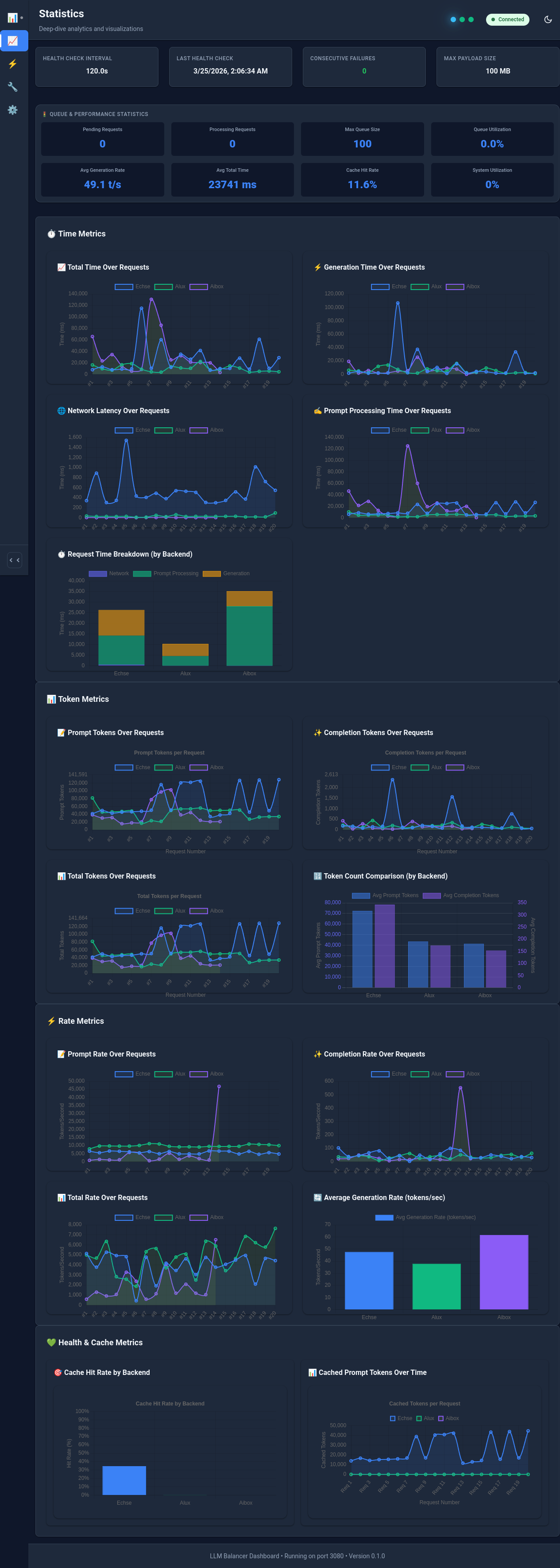
Abbildung: Balancer-Statistiken zeigen das Degradationsmuster bei nicht-gecacheten Token-Raten
Diese Erkenntnis ist der Grund, warum wir derzeit an einer vollständigen Neustrukturierung der Statistikkomponente arbeiten - um sie weiter zu verbessern und Problem-Erkennung noch einfacher zu ermöglichen.
Die Zukunft Lokaler KI
Klar ist, agentische Systeme werden in fast jeder Art von Arbeit Einzug nehmen, während sich Menschen auf höherwertige Aktivitäten konzentrieren. Wir glauben, dass der effektivste Ansatz für viele reale Aufgaben die Mensch-Agent-Kollaboration sein wird, wobei jeder seine Stärken einbringt. Deshalb sind Durchsatz und Responsiveness agentischer Systeme entscheidend.
Infrastrukturerfordernisse
Um diese Zukunft Realität werden zu lassen, benötigen Organisationen zuverlässige Infrastruktur, um verfügbare Hardware effizient zu nutzen. Da agentische Systeme allgegenwärtig werden, wird die Nachfrage nach LLM-Inferenz dramatisch explodieren. Eine ausgewogene, resiliente und beobachtbare Infrastruktur wird entscheidend, um:
- Hardware-Ausnutzung über mehrere Server hinweg zu maximieren
- Konsistente Verfügbarkeit für agentische Workflows sicherzustellen
- Effizient zu skalieren, wenn mehr Agenten dem System beitreten
- Leistungsbottlenecks zu debuggen und zu optimieren
Wir haben diesen Balancer gebaut, um diese Infrastrukturerfordernisse für unsere On-Premise-KI-Deployments zu adressieren.
Kommende Funktionen
Jenseits unserer unmittelbaren Bedürfnisse verbessern wir den Balancer kontinuierlich. Die Statistikkomponente wird für präzisere Problem-Erkennung neu strukturiert. Wir untersuchen auch automatisierte und adaptive Prioritätseinstellung basierend auf realen Durchsatzmessungen.
Fazit
Der Trend zu lokaler KI ist nicht auf einige technologie-fortschrittliche Unternehmen beschränkt. Da Datenschutzvorschriften verschärfen, Datensouveränität kritischer wird und Organisationen kosteneffektive Skalierungslösungen suchen, wird lokale KI für viele Menschen und Unternehmen wichtiger.
Wir teilen diese Arbeit, um zur Community beizutragen, während wir unsere eigene On-Premise-KI-Infrastruktur aufbauen.
Der vollständige Open-Source-Code ist auf GitHub verfügbar: https://github.com/Schafer-List-Systems/llm_balancer
Dieser Blogbeitrag dokumentiert unsere Erfahrungen und Erkenntnisse beim Aufbau von On-Premise-KI-Infrastruktur für unsere agentischen Systeme.